C++位域
500 Words | Read in about 3 Min | View times
Overview
位域是一种特殊的数据结构,可以节省内存资源,使数据结构的存储更加紧凑。本节内容将全面了解一下位域的方方面面。
本系列文章将包括以下领域:
本章其他内容请见 《现代C++》
位域是什么?
位域,Bit field,是一种把数据按位紧凑存储的数据结构,可以大大减小存储数据的内存大小。位域使用结构体关键字struct来声明,乍一看和结构体很类似,不过位域的每个字段需要设置宽度,位域的声明形式如下:
1struct bit_filed {
2 type [field_name] : witdh;
3};
举个例子:
1struct msg_hdr {
2 unsigned int cmd : 8;
3 unsigned int ver : 4;
4 unsigned int ts : 32;
5 unsigned int sz : 32;
6};
定义了一个位域msg_hdr,包含2个2位的字段和2个32位的字段,使用结构体的字段运算符对其进行赋值。赋值时,值的大小不能超过该位域字段的大小上限。 如msg_hrd.cmd为4位的位域字段,值的取值范围为[0, 2^8 - 1],即[0, 255]。
另外,位域字段的宽度不能超过该数据类型的大小。如unsigned int cmd : 64将无法产生警告,因为unsigned int的大小是32位。
位域字段可以没有名字,这时它只用来作填充或调整位置。无名位域字段是不能使用的:
1struct record {
2 unsigned int a : 1;
3 unsigned int : 3; //无名位域,仅用来填充空间
4 unsigned int b : 4;
5};
宽度为0的无名位域字段强制下一位位域字段与下一个类型的边界对齐,即将前后两个位域字段分开在不同的基本类型内存中存储:
1struct record
2{
3 unsigned int a : 4; // 第一个unsigned int,占4位
4 unsigned int : 0; // 无名位域
5 unsigned int b : 4; // 上一个unsigned int剩余的空间不用了,从开始第二个unsigned int开始存放,占4位
6 unsigned int c : 4; // 还是第二个unsigned int中的4位
7 //该位域结构总共8位
8};
位域字段的类型最好使用无符号类型来定义,并且在整个位域结构内部保持一致。
在《左值&右值,左值引用&右值引用》一文中,我们提到过:
位域(bit field)是左值,但是位域不能取地址,也不能将一个非
const引用绑定到位域上。但是const引用可以绑定到位域上,此时会产生一个临时变量。
这是因为位域字段往往不占用完整的字节,有时候也不处于字节的开头位置,所以用&取地址符获取位域字段的地址是没有意义的,编译器会产生如下编译错误error: attempt to take address of bit-field。但是注意整个位域结构是可以取地址的。
位域的大小和对齐规则
位域的对齐规则和内存对齐规则类似,又有一些区别。要计算出位域的大小,首先要理清位域的对齐规则:
-
同一个位域字段必须存储在同一个存储单元中,不可以跨多个存储单元,一个存储单元容纳不下时,应从下一单元开始存放
-
整个结构的大小是位域字段类型中最宽大小的整数倍
-
若相邻的位域字段类型相同,且位宽之和小于等于类型的大小,则后面的字段紧邻前一个字段排列,直到容纳不下
-
若相邻的位域字段类型相同,但位宽之和大于类型的大小,则后面的字段从下一个存储单元开始,其偏移量为类型大小的整数倍
-
若相邻的位域字段类型不同,gcc编译器采用压缩排列,尽量让后面的字段紧邻前一个字段排列,直到容纳不下,而msvc编译器不压缩排列
-
位域字段之间如果穿插非位域字段,则穿插的非位域字段不参与压缩排列,连续的位域字段还是会压缩排列
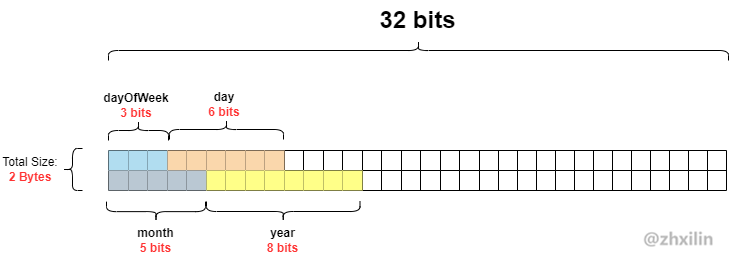
我们以下面这个例子来展示位域的对齐规则:
1struct Date {
2 unsigned int dayOfWeek : 3; //3位,取值[0, 7]
3 unsigned int day : 6; //6位,取值[0, 31]
4 unsigned int : 0; //强制下一字段对齐到下一个类型
5 unsigned int month : 5; //5位,取值[0, 12]
6 unsigned int year : 8; //8位,取值[0, 100]
7};
其内存布局如图所示:
我们还将在《内存对齐》一文中继续介绍更加通用的内存对齐规则。
位域的初始化和重映射
初始化
位域的初始化与普通结构体的初始化方法相同:
1struct msg_hdr msg_hdr1;
2msg_hdr1.cmd = 1;
3msg_hdr1.ver = 1;
4msg_hrd1.ts = 1650031642;
5msg_hrd1.sz = 1024;
6
7struct msg_hdr msg_hdr2 {1, 1, 1650031642, 1024};
利用地址重映射归零
利用重映射可以将位域数据归零
1struct msg_hdr hdr {1, 1, 1650031642, 1024};
2std::cout << hdr.cmd << ", " << hdr.ver << ", " << hdr.ts << ", " << hdr.sz << std::endl; //1, 1, 1650031642, 1024
3
4intptr_t* p = (intptr_t*)&hdr;
5*p = 0;
6std::cout << hdr.cmd << ", " << hdr.ver << ", " << hdr.ts << ", " << hdr.sz << std::endl; //0, 0, 0, 0
同理,可以将位域和等长度的字段作为union的字段,由于union共享内存,利用这个特性将另一个字段的值设置为0,那么位域数据也就自动归零了。
位域的字节序问题
字节序
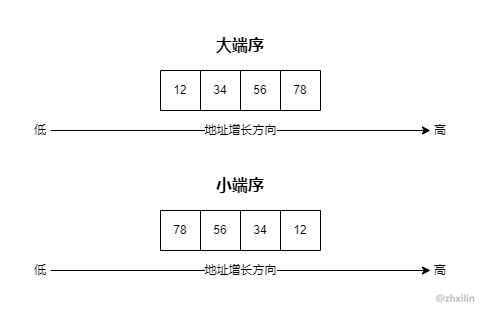
字节序分为大端序(big-endian)和小端序(little-endian)。
-
大端序:高位字节在低地址,低位字节在高地址,简称高低低高。
-
小端序:高位字节在高地址,低位字节在低地址,简称高高低低。
举个例子,0x12345678在两种字节序的存储方式如下:
因为计算都是从低位开始的,电路先处理低位字节效率会比较高。那么如果计算机采用小端序,就可以从低地址先读取到低位字节。
然而大端序更加符合人类的阅读习惯。所以除了计算机内部处理,其他场合几乎都是大端序,比如网络传输和文件储存。
位域的字节序
我们来看一个例子理解位域的字节序:
1struct hdr {
2 unsigned char fin : 1;
3 unsigned char rsv : 3;
4 unsigned char opcode : 4;
5 unsigned char mask : 1;
6 unsigned char payload : 7;
7};//typeof(hdr) = 2
8
9int main() {
10 struct hdr t;
11
12 //位域重映射清空
13 intptr_t* p = (intptr_t*)&t;
14 *p = 0;
15 std::cout << "fin=" << +t.fin << ", rsv=" << +t.rsv << ", opcode=" << +t.opcode << ", mask=" << +t.mask << ", payload=" << +t.payload << std::endl;
16 //fin=0, rsv=0, opcode=0, mask=0, payload=0
17
18 //把2字节的位域结构按字节映射为一个unsigned short,对unsigned short赋值之后,查看位域字段的值来理解字节序
19 unsigned short* s = reinterpret_cast<unsigned short*>(static_cast<void*>(&t));
20 *s = 0x8183;
21 std::cout << "fin=" << +t.fin << ", rsv=" << +t.rsv << ", opcode=" << +t.opcode << ", mask=" << +t.mask << ", payload=" << +t.payload << std::endl;
22 //fin=1, rsv=1, opcode=8, mask=1, payload=64
23
24 return 0;
25}
我们用下面的示例图来展示现在的内存布局:
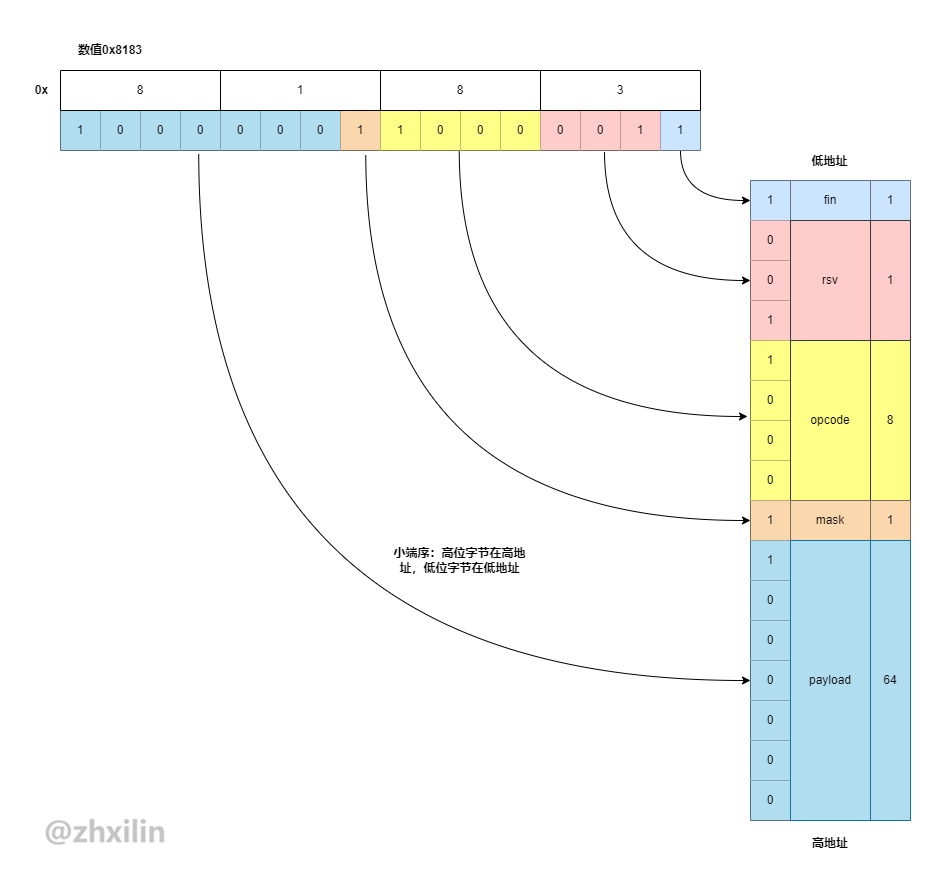
有以下事实,数据0x8183的高位字节是0x81,低位字节是0x83;位域结构hdr在内存中的地址由低到高分别是fin、rsv、opcode、mask、payload。
由于计算机是采用小端序存储的,即高位字节存在高地址,低位字节存在低地址,那么低位字节0x83赋给了低地址所在的fin+rsv+opcode这3个位域字段(宽度共8位),高位字节0x81赋给了mask+payload高地址所在的这2个位域字段(宽度共8位)。每个位域字段在赋值时,按各自的位域宽度,从低到高依次读取指定位数的字节,如fin读取1位,数据为1,rsv读取3位,数据为001,依次类推。
所以0x8183这个值与位域字段应对的二进制关系为
1fin: 1 -> 1
2rsv: 001 -> 1
3opcode: 1000 -> 8
4mask: 1 -> 1
5payload: 1000000 -> 64
所以,理解了字节序,才能在位域赋值时得到预期的结果。